Аннотация. В последние годы массовые нейронные сети (YandexGPT, GigaChat, DeepSeek, ChatGPT и аналоги) стали широко использоваться для генерации текстового контента, в том числе в образовательной практике. Однако стохастический характер генерации и отсутствие прозрачности внутренних механизмов этих моделей затрудняют оценку качества их ответов. Наиболее прямым подходом к такому исследованию является анализ выборки ответов, полученных при многократных запросах, с последующей экспертной оценкой их полезности. При планировании подобного эксперимента возникает классическая задача статистического оценивания: определение объёма выборки, необходимого для обоснованных выводов о доле качественных ответов. Для расчёта используется формула биномиального распределения, требующая априорного знания вероятности успеха, которая в данном случае неизвестна. В статье рассматриваются три метода преодоления этого противоречия: метод максимальной дисперсии, двухэтапный адаптивный метод и пороговый метод с проверкой однородности. Проводится сопоставление достоинств, ограничений и рекомендаций по применению каждого подхода.
Ключевые слова: массовые нейронные сети, генерация контента, педагогические исследования, объём выборки, биномиальное распределение, пороговый метод, коэффициент вариации.
В последние годы широкое распространение получили так называемые массовые нейросети – генеративные модели, доступные широкому кругу пользователей через открытые веб-интерфейсы или программные интерфейсы (YandexGPT, GigaChat, DeepSeek, ChatGPT и аналоги). Указанные сети обучены на больших объёмах текстовых данных и способны генерировать связные ответы на естественно-языковые запросы в режиме реального времени.
В образовательной практике возникает задача системной оценки пригодности такого контента для профессионального использования [1], [3]. В отличие от классических алгоритмов машинного обучения, где метрики качества часто известны априори, массовые нейросети характеризуются стохастичностью генерации и отсутствием прозрачности внутренних механизмов. Наиболее прямым и методологически обоснованным подходом к их исследованию является анализ выборки ответов, полученных при многократных запросах, с последующей экспертной оценкой их полезности для педагогических целей.
При планировании указанного выше эксперимента возникает классическая задача статистического оценивания. Необходимо определить объём выборки, при котором выводы о доле качественных ответов будут статистически обоснованными.


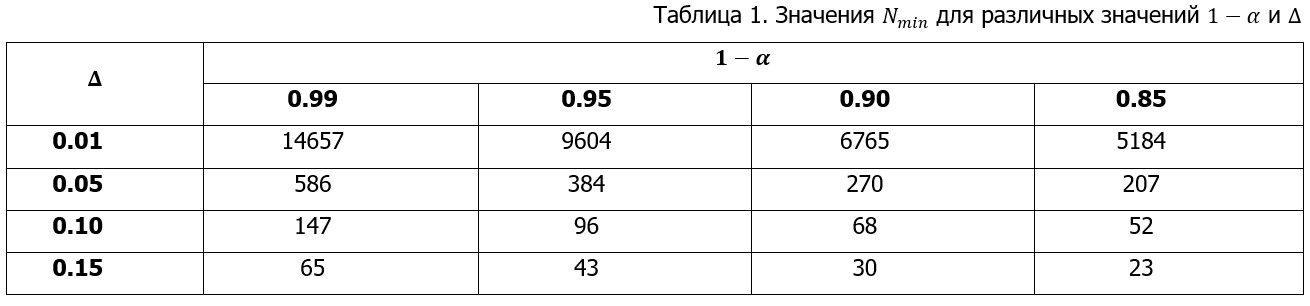








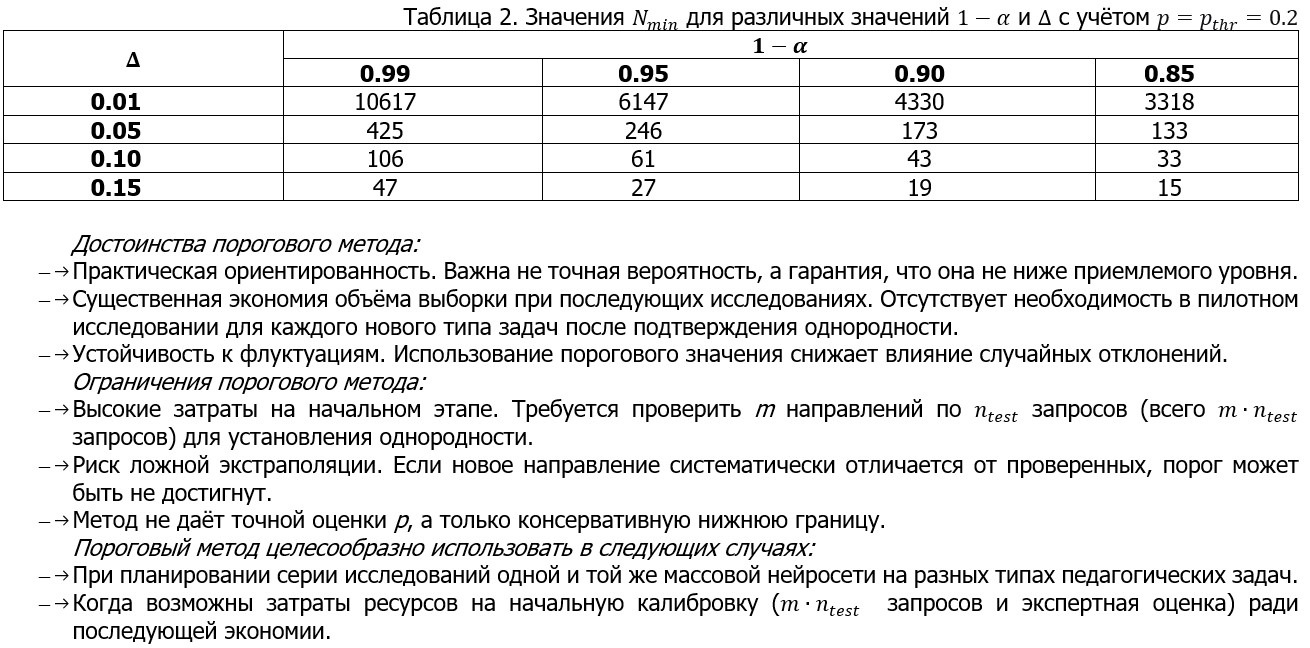
Заключение
В работе рассмотрены три подхода к определению объёма выборки при исследовании массовых нейросетей. Перспективным направлением является разработка методик оценки степени однородности конкретной нейросети для обоснованной экстраполяции результатов на новые типы задач. Отдельного исследования требует формализация процедуры выработки критериев экспертной классификации генерируемых ответов, обеспечивающая воспроизводимость и валидность экспериментальных оценок.
Список литературы:
- Елисеев А.В., Шунина Л.А. Генеративные нейронные сети в образовании: классификация и некоторые особенности использования // Сборник научных трудов, 2023. С. 193-197.
- Корн Г., Корн М. Справочник по математике для научных работников и инженеров // Наука, 1977. 720 с.
- Купалов Г.С. Интеграция нейросетевых технологий в работе учителя: возможности и перспективы // Образовательные ресурсы и технологии, 2023. №1(42). С. 247-253.
Methods for Estimating the Probability of Successful Generation by Large-Scale Neural Networks for Pedagogical Sciences
Lapshenkova O.Ya.,
student of 4 course of the Moscow City University, Moscow
Coauthor:
Lapshenkov V.A.,
student of 4 course of the Russian Technological University MIREA, Moscow
Neserina Ekaterina Dmitrievna,
Assistant of the Department of Informatization of Education of the Institute of Digital Education of the Moscow City University
Abstract. In recent years, large-scale neural networks (YandexGPT, GigaChat, DeepSeek, ChatGPT, and the like) have become widely used for generating textual content, including in educational practice. However, the stochastic nature of generation and the lack of transparency regarding the internal mechanisms of these models make it difficult to assess the quality of their responses. The most direct approach to such research is to analyze a sample of responses obtained through repeated queries, followed by an expert assessment of their usefulness. When planning such an experiment, a classic statistical estimation problem arises: determining the sample size required for making well-founded conclusions about the proportion of high-quality responses. The calculation uses the binomial distribution formula, which requires prior knowledge of the probability of success—something that is unknown in this case. The article discusses three methods for overcoming this contradiction: the maximum variance method, the two-stage adaptive method, and the threshold method with a homogeneity test. A comparison is made of the advantages, limitations, and recommendations for the application of each approach.
Keywords: large-scale neural networks, content generation, pedagogical research, sample size, binomial distribution, threshold method, coefficient of variation.
References:
- Eliseev A.V., Shunina L.A. Generative neural networks in education: classification and some features of use // Collection of scientific works, 2023.: 193-197.
- Korn G., Korn М. Handbook of mathematics for scientists and engineers. Moscow: Nauka, 1977: 720 p.
- Kupalov G.S. Integration of neural network technologies in the work of a teacher: opportunities and prospects // Educational resources and technologies, 2023. №1(42).: 247-253.