Аннотация. В статье раскрывается понятие конкорданса, освещается его возникновение и краткая история. Представлены положения, по которым разграничиваются в смысловом плане такие инструменты корпусной лингвистики, как конкорданс и лингвистический корпус. Подчёркнут вспомогательный функционал конкордансов на базе различных корпусов в ходе переводческого процесса, а также продемонстрирован алгоритм построения персонального конкорданса.
Ключевые слова: конкорданс, перевод, лингвистический корпус, конкорданс-программы.
В настоящее время в связи с масштабной информатизацией использование цифровых технологий в проведении лингвистических исследований является первостепенным. Лингвистическое обеспечение информационных систем, машинная обработка естественного языка, автоматизированное извлечение информации, автоматический анализ и синтез текстов и многие другие технологии работы с языковым материалом в информационной среде – всё это является частью прикладной лингвистики. Несмотря на такие возможности цифровой среды, перед начинающим переводчиком в процессе профессиональной деятельности время от времени возникают определённые трудности. К ним могут относиться: сочетаемость слов, выбор стилистически верного синонима, «выбор правильного переводческого эквивалента терминов, а также принятых в данном контексте штампов письменной речи» [2, с. 48]. Одним из способов решения обозначенных проблем могут служить инструменты корпусной лингвистики, однако, корпусно-ориентированные исследования в сфере перевода всё ещё остаются не столь широко распространёнными. В связи с этим необходимо изучить особенности использования корпусов и функционал конкордансов для повышения качества перевода.
Термин «конкорданс» (англ. concordance (от лат. сoncordia – «согласие»)) имеет большое количество определений. Приведём три варианта дефиниций: С.А. Кузнецов в Большом Толковом Словаре Русского языка указывает, что конкорданс – это «алфавитный перечень всех слов какого-либо текста с указанием контекстов их употребления; тип словаря, представленный в таком виде» [1]. М.В. Копотев в своём пособии определяет его, как «список найденных примеров (вхождений) нужного слова в минимальном контексте», представляющий собой фрагмент из нескольких слов слева и справа [5, с. 235]. Определение В.П. Захарова частично совпадает с вариантом М.В. Копотева: конкорданс – это «список всех вхождений в корпусе (контекстов) заданного в запросе языкового выражения (слово, словосочетание, запрос в виде сложной формулы), возможно, со ссылками на источник» [3, с. 117].
Первоначально «конкордансы» (другое их название – «симфонии») представляли собой книги-списки слов с указанием стихов Священного Писания [3, с. 17]. С течением времени и последовательным отделением от церкви подобные списки слов стали преобразовываться в отдельный жанр и под ними подразумевались «авторские словари», т.е. словари писателей. Для русской авторской лексикографии наиболее значительный вклад оказали конкордансы к поэтическим произведениям Е.А. Баратынского, Ф.И. Тютчева, «Конкорданс к стихам А.С. Пушкина». «Эти конкордансы, выполненные машинным способом, были подготовлены за границей в 70-80‑е годы ХХ столетия» [11, с. 47]. Позднее были созданы конкордансы и к прозаическим произведениям, например, «Словарь-конкорданс публицистики Ф.М. Достоевского».
В настоящее время существует путаница в определениях конкорданса и корпуса. Один термин заменяется другим, многие учёные не используют дефиницию «конкорданс» в своих научных работах. Для того, чтобы корректно представлять результаты исследований, необходимо разграничивать данные термины. Корпус представляет собой набор текстов, в некоторых случаях антологии, которые могут быть отобраны по определённым параметрам (тематика, автор(-ы), время публикации и т.д.). Одна из важных особенностей корпуса – это его представительность, которая позднее стала именоваться «репрезентативность» [3, с. 21]. Репрезентативность считается наиболее важным компонентом при проведении любого эксперимента, так как «степень репрезентативности определяет в конечном итоге валидность результатов» [9, с. 62]. Тем самым, цель корпуса – предоставить репрезентативный материал для последующего анализа и изучения. Конкорданс в широком смысле рассматривается как поисковый инструмент, который позволяет проанализировать частотность употребления того или иного слова, лексемы, найти ключевые слова в контексте (KWIC), коллокации, а также осуществить многие другие вариации лингвистического поиска, на данный момент, в цифровой среде. Современные корпуса неотделимы от конкорданса, так как без последнего нельзя в полной мере провести корпусное исследование.
Исследователь может самостоятельно создать свой корпус текстов, используя современные программные продукты, в том числе программы-конкордансеры. Алгоритм действия можно представить в виде цепочки: подборка текстов из определённой сферы, релевантных для проведения лингвистического исследования => загрузка данных текстов в конкордансер => дальнейший анализ результатов. В итоге, на материале выбранных текстов можно создать собственную базу данных, с помощью которой появится возможность найти аббревиатуры и термины, их употребление, определить коллокации, разработать собственный глоссарий ключевых терминов или проанализировать статистику словоупотребления в текстах определённых жанров и стилей [4, с. 67].
Параллельные корпуса также могут оказать незаменимую помощь при работе с нормативными документами, которые требуют строгого соблюдения принципов и правил оформления. Так, например, при переводе юридической документации (контрактов, договоров и т.д.) можно обратиться за помощью к параллельному корпусу этой сферы и найти точные клише, письменные обороты, которые не допускают варьирования [4, с. 67].
В процессе переводческой работы с русского языка на китайский предполагается использование конкордансов китайского языка, а при переводе с китайского языка на русский – наоборот.
Роль корпусов, как и конкордансов, представлена в их «неоднократном использовании многими пользователями» [7, с. 23], тем самым верная разметка и надёжное обеспечение подобной цифровой системы ставит перед разработчиком задачу по унификации материала. Для корпусов китайского языка существуют особые стандарты по осуществлению и совместимости сегментации с разметкой текстов [7, с. 23]. Помимо этого, важную роль играет набор тэгов частеречной разметки китайского языка (см. таблицу 1). Основная их функция – нахождение коллокаций в конкордансе.
Таблица 1. Основной набор тэгов частеречной разметки в корпусе китайского языка BCC
|
№ |
Тэг |
Часть речи / характеристика |
№ |
Тэг |
Часть речи / характеристика |
|
1 |
a |
Прилагательное |
16 |
o |
Звукоподражание |
|
2 |
b |
Дифференциирующее слово |
17 |
p |
Предлог |
|
3 |
c |
Союз |
18 |
q |
Счётное слово |
|
4 |
Dg |
Модификатор наречия |
19 |
r |
Местоимение |
|
5 |
d |
Наречие |
20 |
s |
Существительное-локатив |
|
6 |
e |
Междометие |
21 |
t |
Существительное времени |
|
7 |
f |
Существительное-директив |
22 |
u |
Частица |
|
8 |
i |
Идиома (чэнъюй) |
23 |
v |
Глагол |
|
9 |
j |
Аббревиатура |
24 |
vn |
Отыменный глагол |
|
10 |
k |
Проклитика (безударное слово, стоящее перед словом с ударением, примыкающем к нему в отношении ударения) |
25 |
w |
Пунктуационный знак |
|
11 |
l |
Обиходное выражение |
26 |
y |
Эмоционально-экспрессивная частица |
|
12 |
m |
Числительное |
27 |
z |
Предикативное наречие |
|
13 |
n |
Существительное |
28 |
un |
Неизвестное слово |
|
14 |
nr |
Имя собственное |
29 |
h |
Энклитика (слово, входящее в одну тактовую группу с предыдущей словоформой) |
|
15 |
ns |
Географическое название |
30 |
vd |
Деепричастие |
Можно продемонстрировать работу с конкордансом на базе корпуса, взяв в качестве примера корпус Пекинского университета языков BCC [6]. Для этого проанализируем лексическую единицу «исследовать» (研究)на сочетаемость с другими дополнениями. Для проведения подобного анализа необходимо ввести в поисковой строке данный глагол и обозначение существительного (N) (см. рисунок 1). В общей статистике можно увидеть частоту использования того или иного сочетания и выявить для себя, например, какой из синонимов стоит использовать при переводе. При переводе фразы «область исследований» можно также выявить, что лучше использовать 研究方面 или 研究领域 (см. рисунок 2).
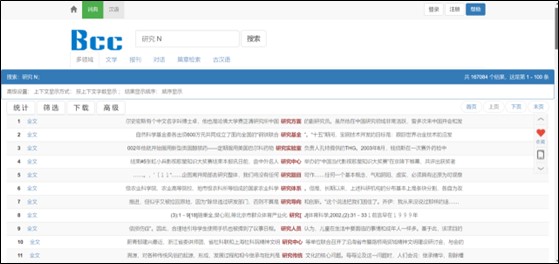
Рис. 1. Лингвистический поиск на базе корпуса BCC
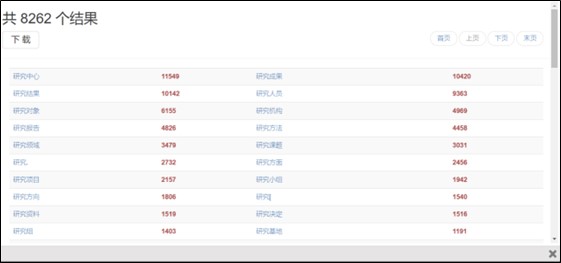
Рис. 2. Числовой показатель коллокаций с ЛЕ 研究
Используя конкордансы параллельных корпусов, можно проанализировать эквивалентные единицы. Например, при переводе с китайского языка на русский, в качестве объекта исследования можно использовать материал русско-китайского параллельного корпуса НКРЯ [8]. Лексическая единица 调查 может переводиться и как «соцопрос», так и как «исследование» (см. рисунок 3).
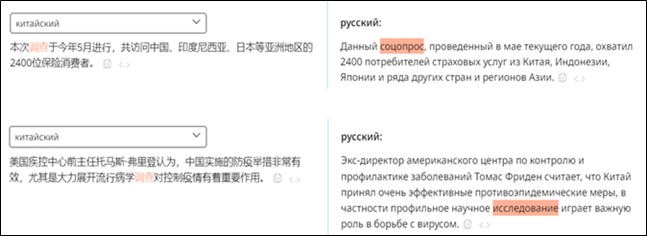
Рис. 3. Лингвистический поиск на базе русско-китайского параллельного корпуса НКРЯ
Для того, чтобы самостоятельно построить конкорданс, можно использовать одно из нескольких доступных программных обеспечений (SketchEngine, WordSmith, SketchEngine и т.д.). Мы возьмём за основу мультимедийную программу «AntConc», созданную Лоуренсом Энтони, профессором университета Васэда (Япония) [12]. В данное программное обеспечение входит не только конкордансер, но и другие вспомогательные средства.
Алгоритм выполнения запроса для построения конкорданса на примере ЛЕ 语言 выглядит так:
- Следует отобрать релевантные для исследования тексты. Для создания базового корпуса с минимальным масштабом можно взять два текстовых документа – у нас это две научные статьи на китайском языке. Файлы формата PDF необходимо конвертировать в формат txt.
- Файлы формата txt загружаются в сегментатор для последующей токенизации (разбивки на минимальные текстовые единицы) китайского текста.
- Далее необходимо произвести загрузку отформатированных текстов в программу.
- В строке поискового запроса необходимо ввести выбранное слово (语言)и нажать кнопку Start.
- Сверху находится панель с разными по функционалу вкладками. Если рассматривать конкорданс в узком смысле, для его анализа нам понадобятся раздел KWIC (Key Word in Context), Plot и Word.
- Ниже представлен таблично-размеченный конкорданс, состоящий из пяти колонок (номер контекста, название файла, левый контекст, искомое слово и правый контекст). Данная разметка позволяет понимать, какой контекст предшествует заданному слову/лексеме и какой следует за этим значением.
- Во вкладке Plot можно проанализировать количество токенов (единиц текста), частотность искомой лексической единицы в числовом значении, нормализованную частоту употребления, дисперсию (мера разброса значений) и частотность лексической единицы в виде штрихкода.
В целом, использование корпусного подхода при переводе, а именно применение такого инструмента корпусной лингвистики, как конкорданс, считается довольно перспективным. Большой функционал конкорданс-программ позволяет рассмотреть языковой материал с разных сторон и провести не только качественный, но и количественный анализ, тем самым демонстрируя многоаспектность данного инструмента. Помимо этого, конкордансы позволяют решить целый ряд переводческих трудностей, связанных с пониманием коллокаций, терминологии и т.д. О.А. Сулейманова считает, что «задача подготовки современного переводчика, способного эффективно использовать все имеющиеся на данный момент технологические ресурсы <…> становится как никогда актуальной в связи с экспоненциально возрастающим потоком информации…» [10, с. 317].
Список литературы:
- Большой толковый словарь русского языка: в 2 т. Т.1 / сост. и гл. ред. С.А. Кузнецов. СПб: Норинт, 2008. 1534 с.
- Груздев Д.Ю., Груздева Л.К., Аванесова Т.П. Перевод на родной язык с электронным корпусом текстов // Вестник Московского Университета. Серия 22. Теория перевода, 2017. №1. С. 33-51.
- Захаров В.П., Богданова С.Ю. Корпусная лингвистика: учебник. 3-е изд., перераб. изд. СПб.: Изд-во С.-Петерб. ун-та, 2020. 234 с.
- Коган М.С., Куликова Е.В. Использование подходов корпусной лингвистики при обучении переводчиков в сфере профессиональной коммуникации // Вопросы методики преподавания в вузе. 2018. Т. 7. №24. С. 65-78.
- Копотев М.В. Введение в корпусную лингвистику: учебное пособие для студентов филологических и лингвистических специальностей университетов. Прага: Animedia Company, 2014. 256 с.
- Корпус Пекинского университета языков BBC. (дата обращения: 04.12.2024).
- Лу И. Принципы создания корпусов китайского языка // Известия Российского государственного педагогического университета им. А.И. Герцена, 2016. №181. С. 22-29.
- Национальный корпус русского языка. (дата обращения: 04.12.2024).
- Сулейманова О.А. Пути верификации лингвистических гипотез: pro et contra // Вестник МГПУ. Серия: Филология. Теория языка. Языковое образование, 2013. №2(12). С. 60-68.
- Сулейманова О.А., Нерсесова Э.В., Вишневская Е.М. Технологический аспект подготовки современного переводчика // Филологические науки. Вопросы теории и практики, 2019. Т. 12, №7. С. 313-317.
- Хроленко А.Т. Автоматизированный конкорданс: опыт создания и практика использования // Филологическая регионалистика, 2012. №2(8). С. 46-50.
- AntConc. (дата обращения: 03.12.2024).
The efficiency usage of concordances in Russian Chinese language pairs translation
Komarova D.O.,
student of 4 course of the Moscow City University, Moscow
Research supervisor:
Vashkyavichus Valentina Yurievna,
Associate Professor of the Department of Chinese Language Institute of Foreign Languages Moscow City University, Candidate of Philological Sciences
Abstract. The author introduces the concept of concordance, gives a brief overview of its emergence and history. The survey shows factors by which concordance and linguistic corpus are differentiated in terms of meaning. The article aims to investigate auxiliary functionality of corpus-based concordances. Constructing algorithm of concordance are shown.
Keywords: concordance, translation, linguistic corpus, concordance tools.
References:
- Kuznetsov S.A. The Large Explanatory Dictionary of the Russian Language: in 2 vol. Vol 1 / comp.. and chief ed.. S.A. Kuznetsov. Saint Petersburg: Norint, 2008. 1534 p.
- Gruzdev D.Y., Gruzdeva L.K., Avanesova T.P. Translating Into Native Language With Corpora // The Moscow University Herald, Series 22, Translation Theory, 2017. №1.: 33-51.
- Zakharov V.P., Bogdanova S.Y. Corpus Linguistics: textbook. 3-rd ed., rewrit. ed. Saint Petersburg: St.-Petersburg State University Press, 2020. 234 p.
- Kogan M.S., Kulikova E.V. Integrating corpus-based approaches into training translators in the sphere of professional communication. Teaching Methodology in Higher Education, Vol. 7. №24.: 65-78.
- Kopotev М.V. Introduction to corpus linguistics: Textbook for students of philological and linguistic specialities of universities. Prague: Animedia Company, 2014. 256 p.
- BLCU Chinese Corpus. (date of the address: 04.12.2024).
- Lu Yi. The Principles For Building Chinese Corpora. // Izvestia: Herzen university journal of humanities & sciences, 2016. №181.: 22-29.
- Russian National Corpus. (date of the address: 04.12.2024).
- Suleimanova O.A. Testing Linguistic Hypotheses: pro et contra // Herald of Moscow City Pedagogical University. Series: Philology. Theory of language, №2(12).: 60-68.
- Suleimanova O.A, Nersesova E.V., Vishnevskaya E.M. Technological Aspect Of Modern Translator’s Training // Philology. Theory & Practice, Vol. 12. №7.: 313-317.
- Chrolenko A.T. Computer-aided concordance: The experience of making and.the practice of usage // Philological regional science, 2012. №2(8).: 46-50.
- AntConc. (date of the address: 03.12.2024).