Второе место «КОД науки» в номинации
«Технические науки и искусственный интеллект» (2026 г.)
Аннотация. В статье рассматривается проблема контролируемой передачи знаний при сжатии языковых моделей на основе архитектуры трансформера. Предложена авторская модель дистилляции, включающая метрику оценки сохранности знаний – Knowledge Retention score (далее – KR-score), встроенную непосредственно в функцию потерь при обучении. Метрика количественно оценивает, насколько точно модель-ученик воспроизводит паттерны внимания модели-учителя для задачно-значимых токенов. Проведено экспериментальное исследование на задаче распознавания именованных сущностей с использованием датасета WikiANN (английский раздел): сравниваются шесть конфигураций моделей, выполнен анализ чувствительности к коэффициенту γ. Предлагаемая модель обеспечивает KR-score 0.7039 против 0.6944 у стандартной дистилляции при практически идентичном F1, а применение прунинга после KR-обучения дает на 4.55 п.п. более высокий F1 по сравнению с прунингом без KR-регуляризации.
Ключевые слова: дистилляция знаний, трансформеры, искусственный интеллект, распознавание именованных сущностей, distilbert, большая языковая модель, прунинг.
Языковые модели на основе архитектуры трансформера BERT, RoBERTa и их производные стали стандартом де-факто в задачах обработки естественного языка [8]. Они демонстрируют высокую точность в задачах извлечения информации, классификации и ответов на вопросы, в том числе применительно к неструктурированным текстовым данным на русском и других языках [2, с. 42], [3]. Вместе с тем развертывание таких моделей в промышленных системах с ограниченными вычислительными ресурсами сопряжено со значительными трудностями: BERT-base содержит 110 млн параметров, занимает около 440 МБ памяти и требует высокой вычислительной мощности при инференсе. Ресурсоэффективность нейросетевых моделей выдвигается в число ключевых требований к промышленным NLP-системам, что отражается в растущем интересе к методам сжатия и оптимизации [4], [5].
Для решения задачи сжатия активно применяется дистилляция знаний (Knowledge Distillation) – передача знаний от крупной модели-учителя к компактной модели-ученику [10]. Полученные таким образом модели способны достигать 95-97% точности учителя при двукратном сокращении числа параметров: DistilBERT и TinyBERT наглядно демонстрируют этот потенциал [11, с. 41], [13]. Структурный прунинг голов внимания предоставляет дополнительный инструмент снижения вычислительных затрат и в сочетании с дистилляцией позволяет достичь еще более компактных моделей [7], [9].
Принципиальной нерешенной проблемой остается отсутствие инструмента управления тем, какие именно знания сохраняются при сжатии. Существующие подходы оценивают качество дистилляции постфактум через итоговые метрики точности на тестовой выборке, но не предоставляют возможности контролировать сохранность задачно-специфических знаний непосредственно в процессе обучения [12]. В результате исследователь узнает о потере критически важных представлений лишь после завершения обучения, что существенно усложняет итеративное улучшение архитектур для специализированных задач – таких как распознавание именованных сущностей (Named Entity Recognition, далее – NER).
Проблематика извлечения и управления знаниями в интеллектуальных системах исследовалась в ряде работ, включая анализ нейро-символических гибридных архитектур и применение трансформеров в системах управления знаниями [1], [6]. Опираясь на полученные результаты, настоящая статья сосредотачивается на задаче контролируемой дистилляции: предлагается авторская модель, в которой метрика сохранности знаний KR-score включена непосредственно в функцию потерь, что впервые позволяет управлять передачей задачно-специфических знаний в режиме реального времени обучения. Цель статьи – разработать и экспериментально проверить метод дистилляции трансформеров с измеримой и управляемой сохранностью извлекаемых знаний применительно к задаче NER.
Предлагаемая модель строится на классической схеме учитель-ученик, расширенной компонентом контроля сохранности знаний. В качестве модели-учителя используется BERT-base-cased (12 слоев, 12 голов внимания, 110 млн параметров), в качестве ученика – DistilBERT-base-cased (6 слоев, 6 голов внимания, 66 млн параметров) [12]. Передача знаний осуществляется на трех уровнях: выходные вероятности (ученик воспроизводит мягкие метки учителя с температурой T = 4), скрытые состояния (согласуются представления соответствующих слоев) и матрицы внимания, когда ученик воспроизводит паттерны внимания учителя для задачно-значимых токенов. Третий уровень является ключевым нововведением и служит основой для вычисления KR-score.
Метрика Knowledge Retention score (далее – KR-score) предназначена для количественного контроля сохранности задачно-специфических знаний в процессе обучения. В контексте задачи NER задачно-значимыми считаются токены именованных сущностей – они формируют множество E ⊆ {1, ..., n} по BIO-разметке обучающей выборки. KR-score для слоя l и головы внимания h равен среднему косинусному сходству между строками матрицы внимания учителя и ученика, вычисленному только по токенам именованных сущностей. То есть для каждого токена из множества E берется строка матрицы внимания учителя и соответствующая строка матрицы внимания ученика, вычисляется косинусное сходство между ними, а затем результаты усредняются по всем токенам сущностей. Итоговый KR-score модели – среднее значений KR(l, h) по всем слоям и головам внимания. Значение лежит в диапазоне [−1, 1], для обученных трансформеров ожидаемый диапазон – [0.5, 1.0]. Высокое значение означает, что ученик точнее воспроизводит внутренние представления учителя для токенов сущностей.
Функция потерь складывается из трех взвешенных компонентов. Первый – стандартная кросс-энтропия на размеченных данных (далее – LCE), отвечает за качество классификации сущностей. Второй – KL-дивергенция между мягкими вероятностями учителя и ученика (далее – LKD), отвечает за передачу знаний через распределения вероятностей [1]. Третий – штраф на основе KR-score (LKR = 1 − KR-score), отвечает за сохранность паттернов внимания для токенов сущностей. Коэффициенты α, β и γ задают вес каждого компонента и подбираются на валидационной выборке. В данной работе использовались значения α = 0.5, β = 0.3, γ = 0.2.
Для верификации предложенного подхода проведено экспериментальное исследование, включавшее четыре этапа: подготовку данных, постановку конфигураций, основной эксперимент и анализ чувствительности к параметру γ.
В качестве датасета использован WikiANN (английский раздел) – мультиязычный бенчмарк для задачи NER, содержащий три типа сущностей: персоны (PER), организации (ORG) и географические объекты (LOC). Объем обучающей выборки – 20 000 предложений, валидационной и тестовой – по 10 000. Датасет доступен в стандартном формате Parquet и совместим с актуальными версиями библиотеки HuggingFace Datasets. Следует отметить, что изначально планировалось использование CoNLL-2003 как традиционного NER-бенчмарка, однако актуальные версии HuggingFace Datasets (начиная с версии 2.20) прекратили поддержку загрузочных скриптов, в связи с чем был выбран WikiANN как функционально эквивалентная и воспроизводимая замена. Идентификация токенов сущностей для вычисления KR-score выполняется автоматически по BIO-разметке: токен включается в множество E при метке, отличной от «O». Токенизация выполнялась токенизатором BERT WordPiece с максимальной длиной 128 токенов. Параметры обучения с обоснованием выбора приведены в таблице 1.
Таблица 1. Параметры обучения
|
Параметр |
Значение |
Обоснование |
|
Learning rate |
5×10⁻⁵ |
Рекомендованное значение для дообучения BERT-подобных моделей. Более высокие значения приводят к нестабильности обучения |
|
Размер батча |
32 |
Баланс между потреблением VRAM (13 ГБ) и стабильностью градиентного спуска при длине 128 токенов |
|
Число эпох |
5 |
С применением ранней остановки при ΔF1 < 0.001 на валидационной выборке |
|
Температура T |
4 |
Значение для мягких меток при дистилляции [4] |
|
Коэффициенты α, β, γ |
0.5; 0.3; 0.2 |
Подобраны на валидационной выборке. γ = 0.2 дает максимальный KR-score при допустимом снижении F1 |
|
Доля удаляемых голов |
40% |
Предварительное исследование уровней 20%, 40%, 60% показало оптимальный баланс при 40% |
|
Оборудование |
NVIDIA RTX 4070 Ti, 13 ГБ, CUDA 12.6 |
Среднее время обучения одной конфигурации около 50 минут |
Для объективного сравнения исследовались шесть конфигураций. Конфигурации 4 и 6 отличаются только наличием KR-регуляризации до прунинга, что позволяет изолированно оценить вклад предлагаемой метрики в устойчивость модели к последующему сжатию:
- BERT-base (учитель) – полная модель, верхняя граница качества.
- DistilBERT без KD – ученик без дистилляции, нижняя граница.
- Стандартный KD – дистилляция с функцией LCE + LKD.
- KD + прунинг 40% – стандартная дистилляция с удалением 40% голов по критерию минимальной нормы активаций.
- KD + KR-score (γ = 0.2) – предлагаемая модель с полной функцией потерь.
- KD + KR-score и прунинг 40% – предлагаемая дистилляция с последующим прунингом.
Для определения оптимального γ проводился анализ чувствительности: конфигурация KD + KR-score обучалась при γ ∈ {0.0, 0.1, 0.2, 0.3, 0.5}. При γ = 0.0 модель эквивалентна стандартному KD, что образует единую шкалу сравнения. Подход к выбору оптимального значения гиперпараметра основан на методе поиска на валидационной выборке, аналогичном применяемому при оптимизации нейросетевых моделей. Результаты основного эксперимента для всех шести конфигураций приведены в таблице 2.
Таблица 2. Сравнение конфигураций моделей
|
Конфигурация |
F1, % |
P, % |
R, % |
Lat, мс |
RAM, МБ |
KR-score |
|
BERT-base (учитель) |
83.28 |
82.04 |
84.56 |
1.29 |
882.0 |
н/д |
|
DistilBERT (без KD) |
80.58 |
79.03 |
82.19 |
2.93 |
4771.3 |
0.6794 |
|
Стандартный KD |
80.41 |
79.39 |
81.45 |
2.91 |
4771.3 |
0.6944 |
|
KD + прунинг 40% |
72.96 |
70.54 |
75.55 |
2.90 |
4771.3 |
0.6027 |
|
KD + KR-score (γ = 0.2) |
80.42 |
79.31 |
81.56 |
2.90 |
5043.7 |
0.7039 |
|
KD + KR-score + прунинг 40% |
77.51 |
75.17 |
80.01 |
2.89 |
5044.7 |
0.6053 |
Примечание: KR-score учителя обозначен «н/д», поскольку метрика измеряет сходство с учителем и для него самого не определена.
На рисунке 1 показано соотношение F1 и KR-score для всех конфигураций. Пунктирная линия – граница Парето: точки на ней соответствуют наилучшему KR-score при заданном уровне F1.
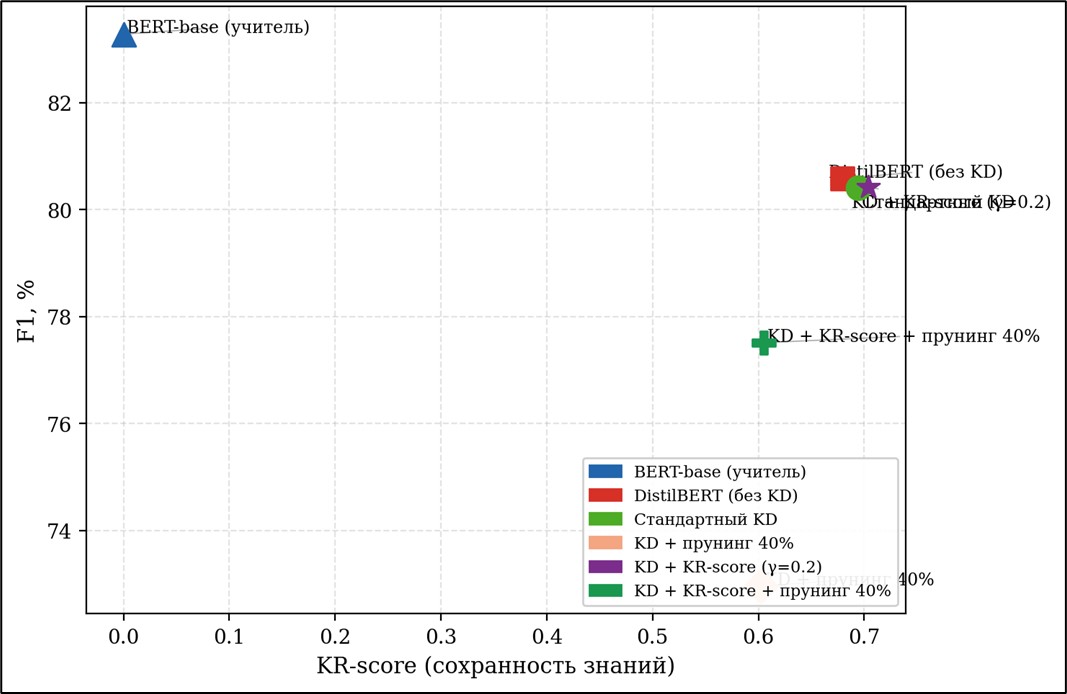
Рис. 1. Соотношение F1 и KR-score для исследуемых конфигураций
Результаты анализа чувствительности к параметру γ представлены в таблице 3 и на рисунке 2.
Таблица 3. Анализ чувствительности модели к параметру γ
|
γ |
F1, % |
KR-score |
Lat, мс |
RAM, МБ |
|
0.0 |
80.64 |
0.6976 |
2.91 |
5317.0 |
|
0.1 |
80.61 |
0.6923 |
2.90 |
5309.2 |
|
0.2 (выбрано) |
80.18 |
0.6996 |
2.90 |
5309.2 |
|
0.3 |
80.39 |
0.6877 |
2.88 |
5309.2 |
|
0.5 |
80.52 |
0.6888 |
2.87 |
5309.2 |
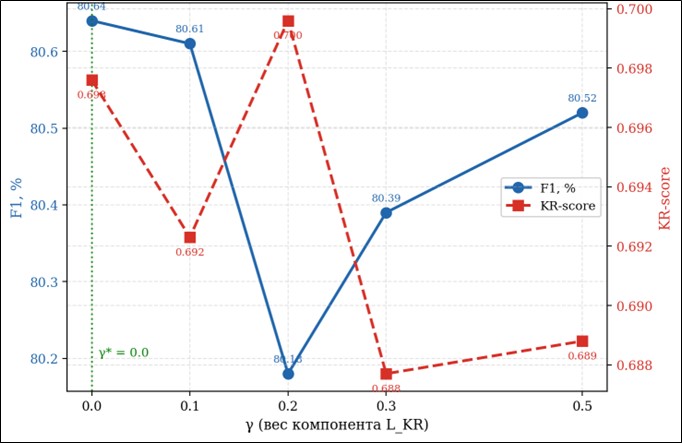
Рис. 2. Зависимость F1 и KR-score от значения γ
Предлагаемая модель (KD + KR-score, γ = 0.2) достигла KR-score = 0.7039, что на 0.0095 превышает значение стандартного KD (0.6944). Значение F1 составило 80.42% против 80.41% у стандартного KD – разница в 0.01 п.п. статистически незначима. Таким образом, включение KR-score в функцию потерь повышает сохранность задачно-специфических знаний без ущерба для точности, а рост времени инференса на 0.01 мс свидетельствует о минимальных операционных накладных расходах подхода.
Наиболее значимым практическим результатом является сравнение конфигураций с прунингом. KD + KR-score + прунинг 40% достигает F1 = 77.51%, тогда как стандартный KD + прунинг 40% дает лишь F1 = 72.96% – разница составляет 4.55 п.п. Модель, обученная с KR-регуляризацией, значительно устойчивее к последующему сжатию – знания, критически важные для задачи NER, сохраняются в головах внимания более надежно. KR-score после прунинга также выше: 0.6053 против 0.6027.
Анализ чувствительности в таблице 3 и на рисунке 2 показывает, что при γ = 0.2 достигается максимальный KR-score среди всех исследованных значений (0.6996) при умеренном снижении F1 до 80.18%. При γ = 0.3 и γ = 0.5 наблюдается снижение KR-score – по всей видимости, высокий вес штрафа LKR нарушает баланс оптимизации и порождает конкуренцию между сохранностью паттернов внимания и качеством классификации. Значение γ = 0.2 признано оптимальным.
Отставание лучшей конфигурации ученика от учителя (BERT-base, F1 = 83.28%) составляет 2.86 п.п., что соответствует уровню, заявленному авторами DistilBERT [12], и подтверждает корректность базовой схемы дистилляции. Ограничением исследования является использование WikiANN с тремя типами сущностей вместо четырех в CoNLL-2003 (отсутствует тип MISC). Это не влияет на сравнительные выводы о KR-score, поскольку все конфигурации тестировались на одном датасете.
По результатам исследования предложена модель дистилляции трансформеров с оценкой сохранности извлекаемых знаний. Метрика KR-score была включена в функцию потерь при дистилляции как управляющий компонент. Экспериментальное исследование охватывает шесть конфигураций и анализ чувствительности к γ. Ключевым результатом является прирост F1 на 4.55 п.п. при прунинге модели, обученной с KR-регуляризацией, по сравнению с прунингом без нее, что подтверждает практическую ценность подхода. Метрика KR-score применима как универсальный инструмент контроля качества дистилляции независимо от задачи и архитектуры.
Перспективные направления дальнейших исследований:
- Проверка предложенного метода на русскоязычных корпусах с применением моделей семейства RuBERT.
- Распространение KR-score на задачи классификации текстов и вопросно-ответных систем.
- Совместная оптимизация прунинга и KR-score как единого алгоритма.
- Исследование альтернативных стратегий формирования множества E задачно-значимых токенов.
Список литературы:
- Мокрецов Н.С., Татарникова Т.М. Алгоритм оптимизации моделей нейронных сетей для обработки текста на естественном языке // Прикладной искусственный интеллект: перспективы и риски: Сборник докладов Международной научной конференции, 2024. С. 280-282.
- Серова В.С., Голлай А.В., Бунова Е.В. Гибридный метод классификации текстовых данных с узкоспециализированной терминологией // Вестник Южно-Уральского государственного университета. Серия: Компьютерные технологии, управление, радиоэлектроника, 2025. Т. 25. №3. С. 42-52.
- Фролов Д.О., Петрова А.Н. Применение самообучающихся трансформеров для извлечения релевантной информации из неструктурированных данных // Молодежь и наука: актуальные проблемы фундаментальных и прикладных исследований: Материалы VIII Всероссийской национальной научной конференции молодых ученых, Комсомольск-на-Амуре, 07-11 апреля 2025 года. Комсомольск-на-Амуре: Комсомольский-на-Амуре Государственный университет, 2025. С. 568-571.
- Хитрых М.С. Методы ускорения обучения нейронных сетей на больших данных (параллельные вычисления, квантование, дистилляция) // Инновационное развитие современной науки: теоретические и практические аспекты : Сборник научных трудов по материалам IX Международной научно-практической конференции, Анапа, 09 августа 2025 года. Анапа: ООО «Научно-исследовательский центр экономических и социальных процессов» в Южном Федеральном округе, 2025. С. 15-20.
- Чуднов И.И. Нейро-символические гибридные системы для динамического управления знаниями // Наука в мегаполисе Science in a Megapolis. 2025. №5(73). (дата обращения: 01.02.2026).
- Чуднов И.И. Применения трансформеров в интеллектуальных системах управления знаниями: модели и алгоритмы // Лига исследователей МГПУ: Сборник статей студенческой открытой конференции. В 3-х томах, Москва, 25-29 ноября 2024 года. М.: ПАРАДИГМА, 2024. С. 449-454.
- Brown N. Efficient Transformer Knowledge Distillation: A Performance Review / N. Brown [et al.] // Proceedings of EMNLP, 2023. (дата обращения: 01.02.2026).
- Devlin J. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding / J. Devlin, M.-W. Chang, K. Lee, K. Toutanova // Proceedings of NAACL-HLT. Minneapolis, 2019.: 4171-4186.
- Hendriks D. Honey, I Shrunk the Language Model: Impact of Knowledge Distillation Methods on Performance and Explainability / D. Hendriks [et al.]. 2025. (дата обращения: 01.02.2026).
- Hinton G. Distilling the Knowledge in a Neural Network / G. Hinton, O. Vinyals, J. Dean. 2015. (дата обращения: 01.02.2026).
- Jiao X. TinyBERT: Distilling BERT for Natural Language Understanding / X. Jiao [et al.]. 2023. (дата обращения: 01.02.2026).
- Poddar S. Towards Sustainable NLP: Insights from Benchmarking Inference Energy in Large Language Models / S. Poddar [et al.]. 2025. (дата обращения: 01.02.2026).
- Sanh V. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter / V. Sanh, L. Debut, J. Chaumond, T. Wolf. 2019. (дата обращения: 01.02.2026).
Model of transformer distillation with assessment of extracted knowledge retention
Chudnov I.I.,
postgraduate student of 2 course of the Moscow City University, Moscow
Research supervisor:
Kapterev Andrey Igorevich,
Professor, Department of Informatization of Education, Institute of Digital Education, Moscow City University, Doctor of Pedagogy, Doctor of Sociology, Professor
Abstract. The paper addresses the problem of controlled knowledge transfer in transformer-based language model compression. An original distillation model is proposed incorporating the Knowledge Retention score (KR-score) metric directly into the training loss function. The metric quantitatively assesses how accurately the student model reproduces the teacher model's attention patterns for task-relevant tokens. An experimental study was conducted on the named entity recognition task using the WikiANN dataset (English section): six model configurations were compared and a sensitivity analysis for the coefficient γ was performed. The proposed model achieves KR-score of 0.7039 vs. 0.6944 for standard knowledge distillation at virtually identical F1, while pruning after KR-regularized training delivers 4.55 percentage points higher F1 compared to pruning without KR-regularization, confirming the practical value of the approach.
Keywords: knowledge distillation, transformers, artificial intelligence, named entity recognition, distilbert, large language model, pruning.
References:
- Mokretsov N.S., Tatarnikova T.M. Algorithm for Optimizing Neural Network Models for Natural Language Processing // Applied Artificial Intelligence: Prospects and Risks: Proceedings of the International Scientific Conference, 2024.: 280-282.
- Serova V.S., Gollay A.V., Bunova E.V. Hybrid Method for Classifying Text Data with Highly Specialized Terminology // Bulletin of the South Ural State University. Series: Computer Technologies, Control, Radioelectronics, 2025. Vol. 25. №: 42-52.
- Frolov D.O., Petrova A.N. Application of Self-Learning Transformers for Relevant Information Extraction from Unstructured Data // Youth and Science: Proceedings of the VIII All-Russian National Scientific Conference of Young Scientists. Komsomolsk-on-Amur, 2025.: 568-571.
- Khitrýkh M.S. Methods for Accelerating Neural Network Training on Big Data (Parallel Computing, Quantization, Distillation) // Innovative Development of Modern Science: Proceedings of the IX International Scientific and Practical Conference, Anapa, August 09, 2025. Anapa:: 15-20.
- Chudnov I.I. Neuro-Symbolic Hybrid Systems for Dynamic Knowledge Management // Science in a Megapolis, 2025. №5(73). (date of the address: 01.02.2026).
- Chudnov I.I. Applications of Transformers in Intelligent Knowledge Management Systems: Models and Algorithms // MGPU Researchers' League: Proceedings of the Student Open Conference. Moscow: PARADIGMA, 2024.: 449-454.
- Brown N. Efficient Transformer Knowledge Distillation: A Performance Review / N. Brown [et al.] // Proceedings of EMNLP, 2023. (date of the address: 01.02.2026).
- Devlin J. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding / J. Devlin, M.-W. Chang, K. Lee, K. Toutanova // Proceedings of NAACL-HLT. Minneapolis, 2019.: 4171-4186.
- Hendriks D. Honey, I Shrunk the Language Model: Impact of Knowledge Distillation Methods on Performance and Explainability / D. Hendriks [et al.]. 2025. (date of the address: 01.02.2026).
- Hinton G. Distilling the Knowledge in a Neural Network / G. Hinton, O. Vinyals, J. Dean. 2015. (date of the address: 01.02.2026).
- Jiao X. TinyBERT: Distilling BERT for Natural Language Understanding / X. Jiao [et al.]. 2023. (date of the address: 01.02.2026).
- Poddar S. Towards Sustainable NLP: Insights from Benchmarking Inference Energy in Large Language Models / S. Poddar [et al.]. 2025. (date of the address: 01.02.2026).
- Sanh V. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter / V. Sanh, L. Debut, J. Chaumond, T. Wolf. 2019. (date of the address: 01.02.2026).